Code Introduction
This page contains information and guidelines to help you understand how SimPROCESD works and how to use it effectively.
Overview
SimPROCESD is a tool for building models of manufacturing environments and for running simulations based off of those models.
A SimPROCESD model consists of a number of connected part handlers that represent various devices/processes/stations in a manufacturing production line. During a simulation parts are generated by sources and move through part handlers until they reach a sink.
Other components are available for modeling more complex behaviors such as maintenance, operating schedules, data collection, and more.
Included Classes/Objects-Types
The package provides the following classes for modeling a manufacturing process.
Parts and part handlers:
Part: Represents a discrete item/part moving through the manufacturing process. Part may represent anything from raw material to finished product and it has a persistent state that can change as the part is processed.
Source: Generates and outputs new parts.
Sink: Receives parts and stores them.
PartProcessor: Processes received parts.
Buffer: Stores received parts and passes them downstream when possible. Has an optional minimum storage time.
DecisionGate: Conditionally allows parts to pass between its upstream and downstream.
PartBatcher: Enforces output to be batches of set size or individual parts.
Other classes:
Maintainer: Performs work order requests such as maintenance.
Group: Allows grouping 1 or more part handlers that can be reused in multiple parts of the manufacturing process.
ActionScheduler: Periodically performs actions on registered objects.
ResourceManager: Manages limited resources.
Probes & Sensors: Take periodic or on-demand readings and record them. The recorded data is accessible during the simulation and after.
Upstream/Downstream
Arrows indicate part flow across part handlers.
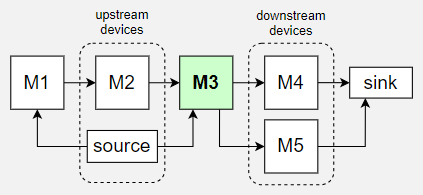
The example above shows (direct) upstream and downstream devices with respect to M3. Upstream part handlers can pass parts to M3 and downstream part handlers are the ones which M3 can pass parts to.
The links between different part handlers are configured by setting the upstream parameter.
source = Source()
M1 = PartHandler(upstream = [source])
M2 = PartHandler(upstream = [M1])
M3 = PartHandler(upstream = [source, M2])
M4 = PartHandler(upstream = [M3])
M5 = PartHandler(upstream = [M3])
sink = Sink(upstream = [M4, M5])
M3can receive parts from bothsourceandM2.Parts are always passed one at a time, however multiple parts may pass between part handlers before simulation time advances depending on cycle times.
To pass multiple parts as a single entity use the Batch and PartBatcher classes.
Upstream list of part handler can be changed after its initialization:
M1 = PartHandler(upstream = [S1, S2])
M1.set_upstream([S1]) # S2 is no longer upstream of M1.
A part handler’s upstream list can not contain itself. A circular flow is still possible if M1
is set as upstream of M2 and M2 is set as upstream of M1.
Multiple Downstreams
Configuring a part handler (Source) to have multiple downstreams:
S1 = Source()
M1 = PartHandler(upstream = [S1])
B1 = Buffer(upstream = [S1], capacity = 5)
In this setup, parts from
S1can go to eitherM1orB1.As part handler output parts, those parts will be passed to one of the downstreams prioritizing part handlers that have been waiting for input parts the longest.
To change the priority of a specific part handler, override the function
<part_handler_instance>.get_sorted_downstream_listTo change the default behavior for all part handlers, override the static function
PartFlowController.downstream_priority_sorter.
Simulation time
Simulation time is the time tracked within the simulation and is independent of how long it actually takes to simulate the model. Simulation time can be accessed through <Environment_instance>.now.
Simulation time is measured in time units. It is up to the model designer to determine what those time units represent (seconds, hours, years, etc.) and to be consistent with that definition throughout the model.
Simple Example
A complete example where parts are created by the Source, passed to the PartProcessor, and then passed to the Sink. The simulation is set to run for 100 time units.
from simprocesd.model import System
from simprocesd.model.factory_floor import Source, PartProcessor, Sink, PartGenerator
system = System()
partGenerator = PartGenerator(name_prefix = 'DefaultPart',
value = 0, quality = 100)
source = Source(part_generator = partGenerator, cycle_time = 1)
M1 = PartProcessor(upstream = [source], cycle_time = 1)
sink = Sink(upstream = [M1])
system.simulate(simulation_duration = 100)
Same example with additional comments:
# System needs to be created first so that other simulation objects
# can register themselves with it automatically.
system = System()
# PartGenerator configured to create new parts with the starting
# value of 0 and a starting quality of 100.
partGenerator = PartGenerator(name_prefix = 'DefaultPart',
value = 0, quality = 100)
# Source will create a new part every 1 time unit.
source = Source(part_generator = partGenerator, cycle_time = 1)
# Create PartProcessor that gets parts from Source and takes 1 time unit
# to process the part before passing it downstream.
M1 = PartProcessor(upstream = [source], cycle_time = 1)
# Sink is the end of the line and can only receive parts.
sink = Sink(upstream = [M1])
# Run the simulation until 100 time units passed.
system.simulate(simulation_duration = 100)
Post-Simulation Analysis
How to go about collecting data during the simulation and retrieving it afterwards.
Simulated Sensors
Sensor example: ConditionBasedMaintenance.py
Integrated Data Collection
SimPROCESD by default records some data about the simulation.
Description |
list_label |
sub_label |
data_point |
|---|---|---|---|
Source outputs a part |
‘supplied_new_part’ |
source name |
(time, part_id) |
Part handler receives a part |
‘received_part’ |
part handler name |
(time, part_id, part_quality, part_value) |
PartProcessor processes a part |
‘produced_part’ |
part handler name |
(time, part_id, part_quality, part_value) |
PartProcessor failure |
‘device_failure’ |
part handler name |
(time, lost_part_ID) |
Work order enters queue |
‘enter_queue’ |
maintainer name |
(time, target_name, maintenance_tag, info_string) |
Work order begins |
‘start_work_order’ |
maintainer name |
(time, target_name, maintenance_tag, info_string) |
Work order completes |
‘finish_work_order’ |
maintainer name |
(time, target_name, maintenance_tag, info_string) |
Buffer level change |
‘level’ |
buffer name |
(time, buffer_level) |
Sink receives a part |
‘collected_part’ |
sink name |
(time, part_quality, part_value) |
Schedule’s state change |
‘schedule_update’ |
schedule name |
(time, state) |
Available resource change |
‘resource_update’ |
resource name |
(time, resources_in_use, max_resources) |
Example of retrieving a table of raw data for a specific part handler.
system.simulation_data['produced_parts']['M1']
# <System_instance>.simulation_data[list_label][sub_label]
# or
# <Environment_instance>.simulation_data[list_label][sub_label]
That data gets stored in simulation data which is a dictionary with the following structure:
Key:
list_label(string)Value: Dictionary
Key:
sub_label(string)Value: List of tuples stored with that
list_labelandsub_labelThe list contains data in the order that it was recorded.
Tuples in the list are
tuple_of_datafrom the example below.
Adding new datapoints to be recorded during the simulation is easy:
# Call the following code on any Asset (PartProcessor, Source, Buffer, etc).
M1.env.add_datapoint('new label', M1.name, (M1.env.now, self._output.quality))
# <Asset>.env.add_datapoint(list_label, sub_label, tuple_of_data)
It is recommended to only store simple types data like integers, floats, and strings. If objects provided to add_datapoint are later changed then the recorded datapoint will change as well.
For example, if the caller stores a list of integers in the datapoint and later updates the list contents, then the recorded datapoint will now point to the changed list. Same thing happens with objects because what is actually stored is a pointer to the object as opposed to a full copy of the object.
To store objects and lists one could make a copy of them first before recording the copy in the datapoint. This way the original can be changed while the copy used as a datapoint will remain the same as when recorded.
One place where new datapoints can easily be recorded is PartProcessor’s callbacks:
M1 = PartProcessor(upstream = [source], cycle_time = 1)
def on_received_part(device, part):
device.env.add_datapoint('received_part_value',
device.name,
(device.env.now, part.value))
# Configure on_received_part to be called every time M1 receives a part.
M1.add_receive_part_callback(on_received_part)
...run simulation...
# Print list of recorded tuples
print(system.simulation_data['received_part_value'][M1.name])
simulation_data Reference
There are built-in functions under GitHub: simulation_info_utils.py that show graphs based on simulation_data.